在大数据技术生态中,Apache Kafka 已从一个高性能的消息队列系统,演变为一个核心的实时数据流平台,扮演着“中枢神经系统”或“数据总线”的关键角色。它专为处理高吞吐、低延迟的实时数据流而设计,有效连接了数据生产者与消费者,是现代数据管道和流处理应用不可或缺的组件。
一、 基本概念解析
- 分布式流处理平台:Kafka 的核心定位。它不仅仅传递消息,更能持久化、存储数据流,并支持在数据移动过程中进行实时处理。
- 发布/订阅消息模型:数据生产者(Producer)将消息发布到特定的类别(称为Topic),而数据消费者(Consumer)则订阅这些Topic来接收和处理消息。生产者和消费者之间完全解耦。
- 日志(Log)数据结构:Kafka 的存储核心。每个Topic下的数据被组织成一个仅追加(append-only)、按序排列的持久化日志序列。这种设计保证了极高的顺序读写性能和数据可靠性。
- 实时数据管道:Kafka 常被用作连接不同数据系统(如业务数据库、Hadoop、数据仓库、实时计算引擎)的可靠管道,实现数据的实时流动。
二、 核心组件详解
Kafka 架构主要由以下几个核心组件构成,共同协作以提供高可用、可扩展的数据流服务:
- Producer(生产者):
- 角色:向Kafka集群中的特定Topic推送数据的客户端应用程序。
- 关键行为:可以指定将消息发送到Topic的哪个分区(Partition),支持同步/异步发送,并可通过配置确认(ack)机制确保数据可靠送达。
- Consumer(消费者):
- 角色:从Topic拉取(pull)并处理数据的客户端应用程序。
- 关键概念:消费者以消费者组(Consumer Group)的形式工作。组内消费者共同消费一个Topic,每条消息在同一时刻只会被组内的一个消费者处理,从而实现消费的并行扩展与负载均衡。
- Broker(代理服务器):
- 角色:Kafka集群中的单个服务节点,负责接收生产者的消息、分配偏移量(Offset)、持久化存储数据,并响应消费者的拉取请求。
- 集群化:一个Kafka集群由多个Broker组成,实现数据冗余、负载均衡和高可用性。
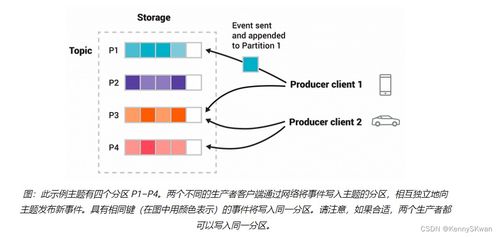
- Topic(主题)与 Partition(分区):
- Topic:数据记录的类别或订阅源名称,是生产者与消费者交互的逻辑单元。
- Partition:Topic在物理上的细分。每个Topic可以被分为多个分区,分布在不同Broker上。分区是Kafka实现水平扩展和并行处理的基础。消息在分区内严格有序,但跨分区不保证顺序。
- ZooKeeper / KRaft(集群元数据管理与协调):
- 传统角色(ZooKeeper):在Kafka 2.8版本之前,Kafka依赖ZooKeeper来管理集群元数据(如Broker、Topic、分区状态)、进行领导者选举和维持消费者组偏移量。
- 演进(KRaft模式):自Kafka 3.0起,Kafka引入了基于Raft共识协议的KRaft模式,逐步取代ZooKeeper,将元数据管理内置于Kafka自身,简化了架构部署与运维。
- Connector与Streams(高级数据处理服务):
- Kafka Connect:一个用于在Kafka和其他系统(如数据库、搜索引擎、文件系统)之间进行可扩展、可靠数据导入导出的框架。它通过丰富的预构建连接器(Connector)简化了数据集成任务。
- Kafka Streams:一个用于构建实时流处理应用程序的客户端库。开发者可以直接在业务应用中利用它进行复杂的事件处理、流聚合、窗口操作等,而无需部署额外的流处理集群。它让Kafka从“数据管道”升级为完整的“流处理平台”。
三、 作为数据处理服务的价值
在大数据体系中,Kafka提供的数据处理服务体现在:
- 解耦与缓冲:在数据生产者和消费者之间建立异步缓冲层,应对流量峰值,防止系统间耦合导致的级联故障。
- 数据持久化与重播:消息可配置持久化存储一段时间,允许消费者按需重播历史数据,为故障恢复、回溯分析和新应用上线提供便利。
- 流处理基础:通过与Kafka Streams或第三方流处理引擎(如Flink、Spark Streaming)无缝集成,为实时监控、实时风控、实时推荐等场景提供低延迟的数据处理能力。
- 数据集成枢纽:借助Kafka Connect,它成为统一的数据接入和分发中心,简化了复杂数据架构的构建与管理。
###
Apache Kafka 以其独特的日志存储模型、分布式架构和丰富的生态组件,成功解决了大数据场景下实时数据流的可靠收集、存储与分发问题。理解其Producer、Consumer、Broker、Topic/Partition等核心组件,以及Kafka Connect和Kafka Streams所延伸的数据处理服务能力,是构建高效、健壮实时数据管道的关键。它已然成为大数据技术栈中连接批处理与流处理、在线与离线系统的核心基础设施。