一、问题背景
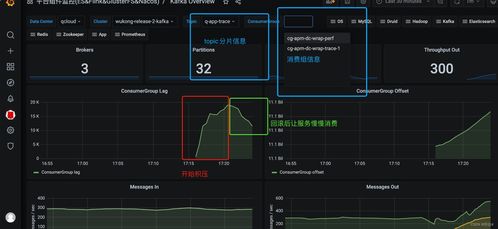
我们团队对线上核心数据处理服务进行了一次重要升级,旨在提升吞吐量与处理能力。升级内容主要包括引入新的流处理框架、优化内部计算逻辑以及调整资源分配策略。服务上线后不久,监控系统发出警报:Kafka消费者组出现严重的消息积压,积压量在短时间内从正常水平飙升至数百万条,并且持续增长,直接影响了下游业务的实时性与数据一致性。
二、问题现象与初步分析
- 监控指标异常:
- 消费延迟激增:Kafka监控面板显示,指定消费者组的
consumer lag(消费滞后)指标急剧上升。
- 消费速率下降:服务自身的处理TPS(每秒事务数)远低于Kafka分区的写入速率。
- 资源使用异常:虽然CPU和内存使用率未达瓶颈,但I/O等待时间和GC(垃圾回收)频率有所增加。
- 初步假设:
- 处理逻辑变更引入瓶颈:新引入的框架或优化后的代码可能存在性能回退或阻塞点。
- 资源配置不合理:升级后的服务实例数、线程池配置或JVM参数可能与新的处理模式不匹配。
- 外部依赖或数据特征变化:处理过程中依赖的数据库、缓存或API响应变慢,或本次上线恰逢数据峰值或数据结构变化。
三、详细排查过程
我们遵循从外到内、从表象到根因的排查路径:
- 基础设施与流量检查:
- 确认Kafka集群本身健康,分区数、副本状态、网络带宽均正常。
- 确认消息生产端速率稳定,未发生突发性流量洪峰。
- 排除网络波动或服务所在宿主机资源争抢问题。
- 服务级诊断:
- 日志分析:检查服务错误日志,发现大量关于数据库连接获取超时的警告,以及与下游某个API交互时偶尔出现的超时记录。
- 线程堆栈分析:对服务实例进行线程Dump,发现大量处理线程处于
BLOCKED或WAITING状态,堆栈指向数据库连接池和HTTP客户端池。
- 性能剖析:使用Profiler工具进行CPU和内存采样,发现大量的CPU时间花费在序列化/反序列化以及等待I/O上,新的流处理框架的某个序列化器开销显著高于预期。
3. 根因定位:
综合以上信息,锁定三个核心原因:
- 数据库连接池瓶颈:升级后的服务并发处理能力提升,但数据库连接池最大连接数配置未相应调高,导致大量线程在等待获取数据库连接,形成连锁阻塞。
- 下游依赖性能退化:服务依赖的某个下游API响应时间(P99)在升级同期有所增长,虽然平均影响不大,但在高并发下拖慢了整体处理链路。
- 序列化效率低下:新框架默认使用的序列化方式对本次处理的数据结构(嵌套复杂对象)效率不佳,消耗了过多CPU资源。
四、解决方案与实施
采取分级、分步的解决策略,优先止血,再优化根治:
- 紧急扩容与参数调整(短期):
- 临时增加数据处理服务的实例数,分担消费压力,快速降低积压量。
- 立即调整数据库连接池参数(如
maximumPoolSize),使其与服务的并发线程数匹配。
- 对消费端配置进行调优,适当降低
max.poll.records(单次拉取最大记录数),减少单批处理压力,换取更平滑的处理。
- 核心优化(中期):
- 替换序列化方案:评估并切换到更高效的数据序列化器(如从JSON切换为Avro或Protobuf),大幅降低CPU开销。
- 引入弹性与降级:对调用下游API的环节配置合理的超时、熔断和降级策略,避免因个别慢请求阻塞整个处理管道。
- 优化批处理逻辑:对非强实时性的处理环节,将“逐条实时处理”改为“微批次聚合处理”,减少I/O和网络交互次数。
- 架构与监控加固(长期):
- 推动下游API服务方进行性能优化与容量评估。
- 完善监控体系,增加对处理链路各阶段耗时(如:消费、反序列化、业务计算、数据库操作、外部调用)的细粒度埋点和告警。
- 建立上线前压测流程,确保未来任何逻辑或框架升级都需通过模拟真实数据流的压力测试,提前发现容量和性能问题。
五、效果验证与
经过上述措施,消息积压量在几小时内开始稳步下降,并在一天内完全消化。服务处理TPS恢复并稳定在预期值的120%,资源使用率回归健康状态。
本次事件的主要教训与如下:
1. 容量评估必须前置:服务能力升级时,需对其依赖的资源(如连接池、线程池)和下游服务进行联动评估和调整。
2. 全链路监控至关重要:仅监控服务本身和Kafka延迟不够,必须能透视内部处理链路的每一个关键阶段。
3. 变更的风险是立体的:代码逻辑变更是核心,但配置、数据特征、依赖方状态同样是风险来源,需要系统化审视。
4. 建立回滚与应急预案:复杂的服务升级应有快速回滚方案,并对可能出现的消息积压、消费延迟等问题预设处理预案(如动态扩缩容脚本)。
通过这次实战,我们不仅解决了眼前的问题,更强化了团队对分布式数据流水线稳定性的系统性保障能力。